The Golden Rule
Amazon Alexaのユーザビリティと新しいパラダイム
はじめに
この記事は、 Amazon Alexa Advent Calendar 2017の22日目の記事です。
今年の5月に アクセシビリティの祭典でAI音声スピーカーについてお話したり、それを受けて AccSellポッドキャストでお話させていただいたりした頃から、主に Amazon Alexa(以下、"Alexa")をベースに関連資料を読んだり、 AVSをRaspberry Piで 動かしたりしていました。
ユーザビリティ的にもアクセシビリティ的にも検討する余地が多いなと思っていたところ、 @caztchaさんが、より広い視点での VUIユーザビリティについて記事書かれました。
この記事についてfacebookでコメントを寄せたところ、そのナレッジをぜひ記事にとcaztchaさんにおっしゃっていただいたことが、この記事のきっかけです。
と言っても、これは今年の10月頃のお話なのですが、諸事情あってAdvent Calendarの記事になりました。
caztchaさんの記事をAlexaをベースに読んでいくことを通じて、あらためてAlexaのユーザビリティについて整理して考えていきます。 その結果、従来のユーザビリティ原則の見方を変えざるを得ないと考えるようになりました。
またAlexa界隈で「ユーザビリティ」というと、要望する機能をどのように音声化するかという 音声インターフェース設計が思い浮かびまずが、この記事はAmazon Alexa全体のユーザビリティについて論じていきます。
![[イメージ写真]](https://blog.motchie.com/images/main-image-usability-for-amazon-alexa-and-new-paradigm.jpeg)
Photo by portalgda on Visualhunt / CC BY-NC-SA
記事の論点
caztchaさんの記事は、特定のVUI製品に依存したものではありません。またスマートスピーカー製品自体からVUIまで多くの点について言及されています。caztchaさんの記事の論点のうち、今回取り上げるものの主語を「Amazon Echo」にしたものが以下です。
- Amazon EchoはVUI単体である
- Amazon Echoは見ただけでは、どう操作していいかわかりにくいのでは
- システムの利用に際して、どう使うのか/どんな結果が得られるのかが予想しにくいのでは
- どう操作すればよいか、また操作によって何が起こるかがわかりにくいのでは
Alexaのフレームワークについて
一般に知られているスマートスピーカーであるAmazon Echoは、クラウドベースの音声サービス「Amazon Alexa」によって動作しています。
Alexaは2つのフレームワークで成り立っています。
- Alexa Skills Kit(ASK)
- Alexaの「能力」と呼ぶべきSkillを開発するためのフレームワーク
- Alexa Voice Service(AVS)
- Amazon Echoのように、Alexaを利用した音声による入出力を製品で可能にするためのフレームワーク。 マイク、スピーカー、インターネット接続があれば同様の製品を開発ができるとされています。これを利用し、Amazon以外のサードパーティによる製品が多数開発されています。以後、本記事では、こうした製品の汎用的な呼称として「Alexa端末」と表記します。
Alexaアプリ
Alexa端末を購入したユーザーは、それを家庭内の無線LANに参加させたり、自分のAmazon.co.jpアカウントに登録したりするために「Alexaアプリ」を利用します。
Alexaアプリは、以下の3つの形態で提供されます。
このAlexaアプリには上記以外にも多数の機能がありますが、ユーザビリティに関連する機能は以下です。
- 発話した指示とAlexaの応答の履歴
- 発話の結果録音された自分の声の確認
- 発話をAlexaが認識した結果が正しかったかどうかフィードバックを行うリンク
- 週間天気予報など、GUIでの表示に適した情報
- Alexaへの指示のサンプル
- Alexaに依頼した買い物リスト、ToDoリスト、リマインダー、アラーム、タイマーなどの状況
- スキルの探索、登録と有効なスキルの管理
- スマートホームスキルの設定と管理
- ヘルプとチュートリアル
Alexa端末を利用する場合には、コンパニオンアプリとも呼ぶべきAlexaアプリを併用することになりますので、VUI単体ですべてを操作するという不安はなさそうです。
メンタルモデルについて
ユーザーが生物学的あるいは日常生活で得てきた経験や知識が活かせる UIは、使いやすいと言われます。それは、これから操作する対象物の操作や、その結果の振る舞いに対する予測が立つためです。逆に、ユーザーが過去の経験から予測した内容に反する振る舞いが対象物に見られると、フラストレーションを感じます。
ここで重要になる「メンタルモデル」について 棚橋弘季さんは、かつて次のように説明されました。
人は未知の状況において行動を起こす際、必ず「こうしたらこうなるはずだ」という予測を立てた上で自身の行動を選択します。簡単にいうと、この「こうしたらこうなるはず」というイメージがメンタルモデルです。未知のモノを使う際にも「このボタンを押すとこうなるのでは?」といったように何らかの操作方法に関するメンタルモデルをイメージした上で操作してみるわけです。
このとき、メンタルモデルと実装モデルが一致していれば、ユーザーは自分の思ったとおりの結果を得ることができます。しかし、反対にメンタルモデルと実装モデルにギャップがあった場合、使い方を間違えていて思ったとおりの結果が得られなかったり、なんとか使えた場合でも使っていてイライラするなどの不満を感じたりします。もっとひどい場合はそもそも思っていた用途で使うモノではなかったなんてこともありえます。…
このメンタルモデルの重要性について、 Jakob Nielsenは、次のように表現しています。
Mental models are one of the most important concepts in human–computer interaction (HCI). Indeed, we spend a good deal of time covering their design implications in our full-day training course on User Interface Principles.
ここまで予備知識をつけたうえで、caztchaさんの記事を読んでみます。
VUI におけるインタラクションのトリガーはユーザーの発話であり、入力時にフィーチャーされる機能は基本的にマイクだけです。UI の中に他の視覚的な手がかりが無い (または少ない) ことが多く、Jacob Nielsen の 10 Usability Heuristics で言うところの「Recognition rather than recall (記憶に依存せず、そこにあるものを見て認識できるようにする)」の担保が不十分になりがちです。つまりシステムの利用に際して、どう使うのか/どんな結果が得られるのかが予想しにくく、ユーザーは根拠 (自信) のないメンタルモデルに全面的に依拠せざるを得ない、という状況に陥りやすいと言えそうです。
このご指摘は、メンタルモデルに関する複数の示唆を含んでいると考えます。Alexa端末をメンタルモデルで考えると、このデバイスに類似したものはこれまで存在していなかったため、過去の経験をそのまま応用することが難しいと考えられます。そのため、ユーザーは新たな体験として、過去の経験を複数組み合わせて端末の使い方を習得していく必要があると考えられます。
Alexa端末のメンタルモデルをどう考えていけばよいか「過去の経験を複数組み合わせる」視点から、視覚と触覚から形成されるメンタルモデルと聴覚と発話から形成されるメンタルモデルとに分けて考えたいと思います。
視覚と触覚から形成されるメンタルモデル
Donald Normanは、著書 The Design of Everyday Things で、 "Principles of user interface design"を示しています。ここに "The visibility principle"が含まれています。
- The visibility principle
- The design should make all needed options and materials for a given task visible without distracting the user with extraneous or redundant information. Good designs don't overwhelm users with alternatives or confuse with unneeded information.
これが「視覚と触覚から形成されるメンタルモデル」の核心であると言ってよいと思います。
これから設計するユーザーインターフェースが、 "The visibility principle"を兼ね備えるために用いられる概念が「シグニファイア( "signifiers")」と理解しています。
かいつまんでご説明すると、設計対象となるハードウェアやソフトウェアのインターフェースを、手に取ったり目で見た際にユーザーに形成されるメンタルモデルが、設計上想定している「デザインモデル」と乖離して使いにくくならないよう、対象物の形状やユーザーインターフェースのデザイン、ボタン等のオブジェクトの形状、ラベル等を工夫することを指します [1] 。
ひるがえって、 Amazon Echoを例にAlexa端末の形状・外観やユーザーインターフェースを見てみると:
- マイクとスピーカー
- マイクのミュートボタン
- セットアップボタン
- 状態を表示するリング状の LED
以上で、この状況では、とても "The visibility principle"を満たしているとは言えないと判断される場合もあると思われます。
なお、アメリカ等で販売されている Echo Showや Echo Spotにはディスプレイが搭載されており、Alexaアプリでのみ表示される、GUI表示が必要なもの(週間天気など)を表示できるほか、テレビ電話機能にも利用されています。
それでは、Alexa端末はユーザビリティが低いのかという点については、次節 「聴覚と発話から形成されるメンタルモデル」で考えていきます。
リクエストの方法について
記事の中で
入力時にフィーチャーされる機能は基本的にマイクだけです。UI の中に他の視覚的な手がかりが無い (または少ない) ことが多く...
という記述があります。
"AVS Documentation"の 「一般的なアプリケーションのサンプル」では、Alexa端末のリクエスト受付方法として、次の3タイプが示されています。
- Push-to-talk
- Tap-to-talk
- 音声起動(ウェイクワード)
例えば、Amazon Echoは既定で音声起動(ウェイクワード)をサポートしており、そのワードは、端末ごとに変更が可能です。執筆時点で
- "Alexa"
- "Amazon"
- "Echo"
- "Computer"
というウェイクワードに変更が可能です。
これ以外に、Amazon Echoシリーズは Tap-to-talkに変更する方法も用意されています。そのほか、執筆時点での具体例としては:
- 外出先を想定したAlexa端末
- Amazon Tapなど、外出先での利用を想定したデバイスは、 Push-to-talkが既定のようです。"AVS Documentation"では、ほかにスマートウォッチ等のウェアラブル機器も想定されています。
- Alexa Voice Remote for Amazon Echo and Echo Dot
- Amazon Echoとの距離が遠い場合、周囲が騒がしい場合、発話が困難なユーザー向けに、Amazon EchoやEcho Dot用のBluetoothリモコンが用意されています。マイクのボタンをタップし、リクエストを発話します。
- スマートフォンアプリからのリクエスト
- Allyや Astraなどのアプリケーションでは、画面上のボタンをタップしてからリクエストを発話します。
以上のように、少なくともAlexa端末では、音声起動(ウェイクワード)以外のリクエスト開始方法があります。
「ボタンを押して話しかける」既存UIで考えると、既存メンタルモデルは、トランシーバーなど( Push To Talk)でしょうか。
ただし、そうは言ってもハードウェアのボタン1つだけであり、このボタンでAlexaの全機能やオプションが把握できる状況ではありません。
聴覚と発話から形成されるメンタルモデル
つまりシステムの利用に際して、どう使うのか/どんな結果が得られるのかが予想しにくく、ユーザーは根拠 (自信) のないメンタルモデルに全面的に依拠せざるを得ない、という状況に陥りやすいと言えそうです。
Alexa端末の外観やリクエスト受付がクリアされたところで、いよいよ聴覚と発話から形成されるメンタルモデルについて考えます。
「ユーザーは会話を通じてAlexa端末とコミュニケーションできます」と言っても、執筆時点では、人間のように自由に会話ができません。理解できることは限られており、会話の形式にもルールがあります。
Alexaが理解できることは、端的には ビルトイン機能と、エンドユーザーが Amazon.co.jpからインストールした スキルということになります。
このうち、Alexaの「能力」である スキルがどんどん増やせることがAlexaの特長の一つとして挙げられているものの、現状自分のアカウントでどのような スキルが利用できるかについては、記憶やAlexaアプリでの確認に頼ることになります。ここを指して システムの利用に際して、どう使うのか/どんな結果が得られるのかが予想しにく
い側面はあると思われます。
ただ、これは言わばスマートフォンとスマートフォンアプリの関係と同じと考えられるのではと思います。 ユーザーのスマートフォンは、共通の基本機能はありますが、その大半はユーザーが選択したスマートフォンアプリで構成されます。 そのため、スマートフォンアプリの導入時点で「どう使うのか/どんな結果が得られるのか」理解しているものの積み重ねが、スマートフォンの機能の大半を占めるとも考えられそうです。
同じくスマートフォンのメタファーで考えると、ユーザーが、自分のスマートフォンにインストールしている全アプリの全機能を把握し利用しているというケースも考えにくいです。それは「たくさんのアプリをインストールしたものの、覚えて利用するのはごく一部」という状況と考えられ、必ずしもNormanの言う all needed options and materials for a given task visible
でなくても、特段ユーザビリティに問題ない可能性もあります。
つまり、Alexaとスキルの関係も、上記スマートフォンとスマートフォンアプリと同じモデルで考えることができると考えます。自分のAlexa端末で利用できるスキルは、ビルトインスキルはあるものの、大半はユーザーが自ら導入したものになります。この前提では、ユーザーは自分のAlexa端末にどのような指示をすればどのような結果が得られるかについては、大半は理解していると考えられます。
またスマートフォンアプリと同じく、ユーザーがビルトインおよび自分が導入したスキルを含め、すべての指示を記憶していないケースが多くあると考えられます。この点に関して、Alexaアプリでは、使える指示を「試してみよう!」として定期的に表示しています。
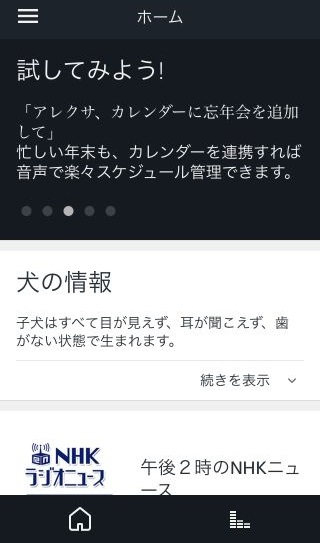
また、音声での指示の途中で気づいた不足しているスキルについて、 Amazon.com: Alexa Skillsでは "Alexa, recommend some skills."、 "Alexa, help me relax."などのスキルをサジェストするスキルを提示しており、音声でスキルを追加する方法があるようです。
ユーザビリティの新しいパラダイム
ここまで、caztchaさんの記事の論点から始まり、Normanのユーザビリティ原則やメンタルモデルをベースにAlexaについて考えてきました。
ただ、ここまで見てくると、1つの疑問がわきます。すなわち、Amazon Echo単体ではなくAlexa端末とAlexaアプリをセットで捉えていくと、それほどユーザビリティ上問題がないのではないか?という点です。
例えば記事にあったNielsenの"Ten Usability Heuristics"にある"Recognition rather than recall"で考えると、確かにAlexa端末自体には備わっていませんが、Alexaアプリでは確認することができます。
同様にNormanの"The visibility principle"についても、Alexa端末自体ではとても確認できませんが、Alexaアプリでは確認することができます。
こうした歴史のあるユーザビリティ理論は、工業製品やGUIソフトウェアといった、それ自体で完結しているもののユーザビリティ研究から生まれた原則と推測されます。しかし、今回のAlexaはじめ、例えば無線LANアクセスポイントとコンパニオンアプリといったように、複数のコンポーネントで1つのシステムを構成するものが増えてきています。そうした、複数コンポーネントによるシステムのユーザビリティ評価では、そのうちの単体を捉えてユーザビリティを議論するのは危険である可能性を考えています。
これはちょうど、以前私がアクセシビリティの分野で提唱した マルチモダリティ・アーキテクチャと状況が同じです。これも同じく、複数のコンポーネントで1つのシステムが構成される場合に、その中の個別の要素ではなく、システム全体として複数のモダリティをサポートすることで、アクセシビリティを評価した方がよいと思われます。
加えて、先ほど書いたように、システムの持つ機能に関しても従来と変わってきました。すなわち、従来のユーザビリティ理論が基礎とする工業製品やGUIソフトウェアは、設計段階からユーザーが利用するまで、およそ機能が変わらないと考えられます。したがって、それらの理論は、その機能を如何にユーザーに伝えるかに苦心した結果と解釈されます。
ところが、スマートフォンやAlexa端末などは、標準機能はあるものの、ユーザーが機能を追加することができ、その過程でユーザーは個々の機能を理解し納得して追加していくことになります。したがって、工場で実装された機能とは、ユーザーの理解がその点で全く異なります。
そうして追加された機能の状況がシステムのコンポーネントによって明らかとなり、その主要な使い方が確認できれば、これもユーザビリティ上問題が少ない可能性を考えています。
以上、Alexaのユーザビリティを考えていくと、ユーザビリティの捉え方が変わったというお話でした。
脚注
[1] 「シグニファイア」と「アフォーダンス」の関係および「誤解されたアフォーダンス」等については、同じくcazchaさんの アフォーダンスを意識するあるいは アフォーダンスからシグニファイアへ等をご参照ください